
9.11 ワイド文字

国際化の対応
今までの時代は、全てのコンピュータで確実にサポートされている文字コードは ASCII コードだけであり、英語以外の言語はシステムに依存する問題でした。しかし、グローバル化が進む中で国際的なソフトウェアの開発が頻繁に行われるようになると、地域ごとで異なる情報を効率的に管理する方法が求められてきます。
そこで、国際的なアプリケーションの開発を行う場合は、C言語でもワイド文字を扱う方法を学習する必要があります。char 型の文字は 1 バイトで構成されるため、一意に表現することができるのは 255 個の文字です。アルファベットと記号程度であれば、確かに 1 バイトで表現できるため効果的ですが、日本語のような多くの文字が存在する言語を扱う場合 255 個では明らかに不足しています。
日本語のような標準では定められていないシステム固有の拡張文字セットを用いるにはワイド文字を用います。ワイド文字とは 1 文字の表現が 2 バイト以上の文字型です。ワイド文字は stddef.h ヘッダファイルで定義されている wchar_t 型で表されます。
ワイド文字は char 型の文字とは異なるため、ワイド文字型の定数を記述するには、文字定数の前に L を付けます。wchar_t 型のリテラル文字列を記述する場合も同様で、二重引用符の前に L を指定します。これらは、例えば、次のようにして変数に保存することができます。
wchar_t wc = L'猫'; wchar_t wstr[] = L"あなたのひざの上の猫";
ただし、ワイド文字型は私たちがこれまで使った文字や文字列とは異質のものであるということを認識してください。文字数を数える場合、ワイド文字は 1 文字 1 バイトではありません。よって strlen() 関数を使うことはできません。ワイド文字を使う場合、これまで使ってきた文字列関連関数を使うことはできないのです。
#include <stdio.h>
#include <stddef.h>
int main() {
wchar_t wc = L'猫';
printf("wchar_t size = %d\n" , sizeof wc);
return 0;
}
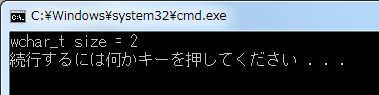
コード1は wchar_t 型の変数を宣言し、これをワイド文字定数で初期化しています。sizeof 演算子を用いて変数のサイズを調べていますが、個のプログラムの結果を見ればワイド文字列が 1 バイトではないことを確認することができるでしょう。
しかし、ワイド文字やワイド文字配列はこれまでのように文字列関連関数で編集したり、入出力を行うことができません。ワイド文字を扱うプログラムはワイド文字専用の関数を使わなければなりません。ワイド文字専用の関数は、従来の文字列関連関数に w を付加するという命名規則を持っています。例えば printf() 関数のワイド文字バージョンは wprintf() 関数に対応し、同様に scanf() 関数は wscanf() 関数に対応します。
int wprintf( const wchar_t *format [, argument]... );
int wscanf( const wchar_t *format [,argument]... );
wprintf() 関数も wscanf() 関数も、文字や文字列に wchar_t 型を用いることができるという点を除いて printf() や scanf() 関数と同じです。しかし、期待するように wprintf() 関数を使ってワイド文字列を標準出力に表示しようとしても、驚いたことに wprintf() 関数は何もしないでしょう。ワイド文字を使う場合はロケールの設定を行わなければなりません。
ロケールとは、特定の地理的地域での地方独特の規則や言語を反映した規則を表します。日本語のワイド文字を使うには、日本語がサポートされているシステムでロケールを "japanese" に設定しなければなりません。ロケールの設定は locale.h ヘッダファイルで宣言されている setlocale() 関数を使います。
char *setlocale( int category, const char *locale );
category はプログラムのロケール情報のどの部分を変更するのかを定数で指定します。locale にはロケールを指定します。関数は有効なロケールとカテゴリを指定すると、ロケールに関する文字列へのポインタを返します。無効な場合は、NULL ポインタを返し設定を変更しません。
category には次のいずれかを指定します。
| 定数 | 意味 |
|---|---|
| LC_ALL | すべてのカテゴリ |
| LC_COLLATE | strcoll()、_stricoll()、wcscoll()、_wcsicoll()、strxfrm() の各関数 |
| LC_CTYPE | 文字処理関数 |
| LC_MONETARY | localeconv() 関数が返す通貨形式情報 |
| LC_NUMERIC | 書式付き出力ルーチンとデータ変換ルーチンの小数点文字、localeconv() 関数が返す非通貨形式情報の小数点文字 |
| LC_TIME | strftime() 関数と wcsftime() 関数 |
ロケールの設定が実際に値得る影響は実行環境によって異なります。ロケール文字には例えば "japanese" など、実装で定義されている値を指定することで、言語を日本語に設定することができます。locale に NULL 文字列を指定すると、そのロケールは処理系定義のネイティブ環境になります。より確実なプログラムを作るには、setlocale() 関数の戻り値を調べ、ロケールの設定が失敗した場合の処理も記述するべきでしょう。
#include <stdio.h>
#include <stddef.h>
#include <locale.h>
int main() {
wchar_t wcat = L'猫';
wchar_t *wstr = L"あなたのひざの上の";
setlocale(LC_ALL , "");
wprintf(L"%s%c\n" , wstr , wcat);
return 0;
}
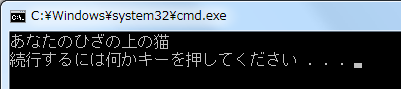
コード2では、 setlocale() 関数を使ってすべてのカテゴリのロケールを日本語に設定しています。その後 wprintf() 関数を使ってワイド文字定数とワイド文字配列を標準出力に表示しています。こうすることによって、日本語文字を扱うことができるようになります。もちろん、実行するシステムが日本語をサポートしていなければ setlocale() 関数は失敗します。