
6.7 ポインタの型変換

6.7.1 ポインタの型変換を利用する
ハードウェアに近い低水準なプログラムを理解する上で最も重要なことはメモリ構造を理解することです。C言語は高水準言語に属しますが、その性質はアセンブリ言語に近く、ハードウェア寄りの低水準な処理も得意としています。その代表的な概念がポインタです。
ポインタを十分に学習すれば、C言語において型とはコンパイラが変数やポインタにアクセスする時に操作するべきサイズを知るための情報にすぎないことがよくわかります。例えば、32 ビットコンピュータにおける int 型の配列 iArray[2] のサイズは合計 8 バイトであり、これを char 型のポインタとして扱うことによって 8 つの要素を持つ char 配列のように扱うこともできます。
#include <stdio.h>
int main() {
int iCount , iArray[2] = { 0x02040810 , 0x20408000 };
unsigned char *cp = (unsigned char *)iArray;
for(iCount = 0 ; iCount < 8 ; iCount++)
printf("cp + %d = %d\n" , iCount , *(cp + iCount));
return 0;
}
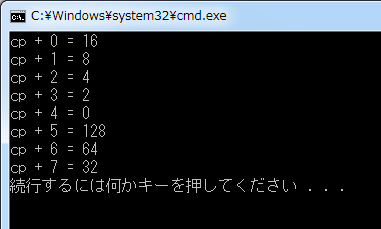
コード1は int 型の配列 iArray の先頭要素へのアドレスを char 型のポインタ cp に代入しています。char 型を中心に考えた場合 2 つの要素を持つ int 型の配列は、32 ビットコンピュータでは 8 つの要素を持つ配列として操作することができるため、for ステートメントでは cp + 8 までの値をバイト単位で表示しています。
このように、強制的にポインタを変換することでバイト単位やワード単位で値を取り出すということができるようになります。型は一度に操作するバイトサイズを示すための情報にすぎないということが、このようなプログラムを作ってみるとよく理解できるでしょう。ただし、int 型から目的のバイトを抽出する場合は、通常はシフトや型キャストだけで実現できるためコード1のようなやり方は稀です。
ある記録方式を採用しているコンピュータでこのプログラムを実行すると、不思議な現象が発生します。例えば Microsoft Windows が動作する Intel x86 互換 CPU の場合、上のような実行結果が表示されるでしょう。プログラムを見れば、メモリには 表1のように先頭から 2、4、8... と順番に値が格納されていることを期待しますが、結果を見ると表2のように 16、8、4、2... と逆順に配置されていることが確認できます。なぜこのような結果が得られるのでしょうか?
| iArray[0] | iArray[1] | ||||||
|---|---|---|---|---|---|---|---|
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 0 |
| iArray[0] | iArray[1] | ||||||
|---|---|---|---|---|---|---|---|
| 16 | 8 | 4 | 2 | 0 | 128 | 64 | 32 |
Intel の CPU はリトルエンディアンと呼ばれる方法でメモリに情報を記録しています。リトルエンディアンとはマルチバイト(2バイト以上の情報)を保存する時、下位バイトから順に保存するという性質を表します。これとは逆に、全ての情報を表1のように上位バイトから順に保存する形式をビッグエンディアンと呼びます。昔の PDP シリーズや Motorola などはこの方法を採用していました。今では、触れる機会は少ないと思われますがビッグエンディアン形式を採用したコンピュータでコード1を実行すれば、上記した結果とは異なる結果を得られるでしょう。
文字などのバイト単位の情報を扱う場合は気にする必要はありませんが、マルチバイトをポインタなどで直接扱ったり、メモリダンプなどを使ってデバッグを行う場合はこのような知識が求められることがあります。
ポインタ型から他のポインタ型への変換はプログラマの責任で行うことができましたが、ポインタから整数への変換などを行うことは可能でしょうか?原則としてはポインタと整数は相互交換可能ではないと定められています。しかし、物理的にメモリアドレスは数値で表現されているため、多くの処理系では整数との相互交換を実現することができるでしょう。しかし、移植性などを重視するのであれば、処理系依存のコードは避けるべきです。
ただし、ポインタと整数型の相互交換において 0 は唯一の例外であるとされています。通常、ポインタは何らかの変数を指していますが、必ずしも有効なアドレスを保有できるとは限らないのです。何らかの有効なポインタを返す関数を作る場合、受け取った引数が不正な値だったために関数の処理を履行できない場合、関数は何を返せばよいのでしょうか?少なくとも、でたらめな値を返すことは避けなければなりません。そこで使われるのが 0 のポインタです。
0 を格納するポインタは、有効なポインタと比較すると等しくならないことを保証しています。つまり、ポインタが有効であれば 0 とは等しくならないのです。
ポインタに使われる 0 には NULL という別名が与えられています。この NULL という識別子(NULL は識別子であり、キーワードではない)は、通常はマクロとして定義されています。マクロについては「8.2 マクロ定数」で詳しく解説しますが、コンパイル時に NULL は 0 に置き換えられているため NULL という識別子と 0 は等しいと考えてください。(NULL == 0) は成立します。
ポインタが有効かどうかを調べたければ NULL と比較します。同様にポインタを無効にしたければ NULL をポインタに代入します。
char *str = NULL;
有効なオブジェクトを参照できないポインタには NULL を代入することで無効なポインタであることをアピールできます。NULL ポインタを参照することはできません。NULL ポインタを参照した結果は未定とされています。ポインタを返すはずの関数が処理に失敗し、適切なポインタを返せないときに NULL を返すことによってエラーを通知する方法は使い古されているので、ポインタと NULL の比較はプログラムの中で頻繁に行われることでしょう。