
2.6 変数

2.6.1 データを記憶する
どのような複雑なプログラムも、その基本的な動作は情報をコンピュータに入力し、プログラムがこれを解析し、望まれる形に変換して出力するという工程の組み合わせで成り立っています。高品質でグラフィカルなゲーム画面も、デジタル音楽プレイヤーで再生している音楽も、インターネットによるコンテンツの送受信も、あらゆるデジタル処理の基本はデータの入力・計算・出力です。
プログラムが情報を受け取り、何らかの計算を行うには、情報を記憶する方法が必要になります。そこで、プログラムは一時的なデータを変数(variable)に保存することで、演算結果や入力された値を記憶しておくことができます。
変数とはメモリの特定の記憶領域の代名詞のようなものです。変数は識別子で区別され、コンパイラは変数と物理的な記憶領域を関連付けることによって情報の書き込みや読み出しを正しく行います。開発者は記憶装置の物理的な構造を意識することなく利用することができるようになります。
変数が指す実際の記憶装置には物理的な容量が存在します。ある情報の保存には 4 バイト必要かもしれませんし、別の情報の保存は 1 バイトで十分かもしれないのです。割り当てる記憶領域のサイズは、変数の宣言(declaration)によって決定されます。 宣言によって、プログラムで使用する何らかの新しい名前を予約できます。変数を利用するには、最初に変数を宣言しなければならないのです。
C++ 言語の宣言の概念は複雑なので、この場ですべてを理解することは難しいでしょう。まずは、データを保存するための変数を用意するには、変数を宣言するということを覚えてください。変数の宣言は次のような形になります。
型 変数名 ;
型とは、変数が保存するデータの種類を表します。変数が数値を保存するのか文字を保存するのかなど、扱うデータによって適切な型指定子(type specifier)を設定しなければなりません。
この場では C++ 言語のキーワードとして用意されている基本的なデータ型を用いましょう。リテラルで説明したような整数や文字型などの基本的なデータを保存するには、単純型指定子(simple type specifier)と呼ばれる、事前に用意された型の名前を使います。例えば、整数型を表す int キーワードや、浮動小数点数型を表す double キーワードなどがあります。
変数名は、この宣言によって新しく登録する変数の名前を指定します。変数名のような、宣言によって付けられた名前を識別子(identifier)と呼びます。変数名の他にも、プログラムの冒頭にある main() 関数の main という名前も識別子に該当します。識別子によって、プログラム内で作られた様々なデータや機能を識別し、必要な時に呼び出すことができるようになります。
整数型の値を保存する value という名前の変数を宣言するには、次のように宣言文を記述します。
int value;
この宣言文は、整数を表す int 型の value 変数を宣言しています。この宣言文の型指定子には整数型を表す int キーワードが用いられているため、value 識別子は整数を保存するための記憶領域の名前として認識されます。
変数名は自由に命名できますが、使える文字や記号が決められています。識別子にはアルファベット、数字、アンダーバー _ を使うことができます。ただし、識別子の 1 文字目には数字を使うことができません。
以下の識別子は、すべて有効です。
- value
- user1
- live4you
- i
- AVATAR_IMAGE
- _test
識別子は、アルファベットのほかに数字やアンダーバーを使えるので user1 や _test なども有効な名前です。
次のような識別子は無効です。
- 2nd
- love+
- int
識別子の 1 文字目に数字を使うことはできません。必ずアルファベットかアンダーバーのいずれかで始まる必要があり、数字が使えるのは 2 文字目以降です。識別子に使える記号はアンダーバーだけなので、その他の記号を使うこともできません。加えて、C++ 言語の使用であらかじめ定められているキーワードである int や return なども識別子にはできません。
また、アルファベットの大文字と小文字は区別されます。例えば Value 変数と vaLue 変数と VALUE 変数は、すべて異なる変数であると解釈されます。
大文字と小文字の組み合わせは任意ですが、慣習として小文字から初めて、複数の単語を組み合わせるときに 2 つめの単語の頭文字を大文字にします。こうすることによって abstractStorageFactoryInstance などの長い名前でも読みやすくなります。
標準の言語仕様では識別子の長さは制限されていませんが、実際には C++ コンパイラ(処理系)によって識別子の長さが制限されることがあります。言語仕様では少なくとも 31 文字までは認識するように定められており、Visual C++ では少なくとも 247 文字までは認識することを保証しています。コンパイラが制限するよりも長い識別子が与えられると、通常は制限を超えた文字が無視されます。不必要に長い名前はコードを醜くするだけなので避けるべきでしょう。
変数名は、変数に保存する値の内容を連想できるような名前をつけるべきです。本書内のサンプルは学習用なので短くて簡素な変数名を多用しますが、実践の開発では a や xxx のような意味のない名前よりも、userName や backgroundColor のような、その変数に何が保存されるのか理解できる良い名前を考えてください。
2.6.2 変数に値を設定する
作成した変数にデータを保存するには、変数に値を格納する必要があります。前述したように、変数とはデータを保存するための記憶領域に名前を付けたものです。変数の宣言によって記憶領域を確保しても、そこに有益な情報は保存されていません。
変数にデータを保存するには代入演算子(assignment operators)を用います。代入演算子と呼ばれる演算子はいくつか種類がありますが、単に代入演算子と言えば単純代入(simple assignment)を行う = 演算子のことを表します。= 演算子は、変数に保存されている値を書き換えます。
変数 = 式 ;
このとき = 記号の左に宣言済みの変数名を指定し、= 記号の右側に変数のデータ型に互換性のある値となる式を指定します。例えば、変数が int 型であれば = 記号の右に置かれる値は 10 や 100 のような整数型でなければなりません。int 型の value 変数に 10 を保存するには次のように記述します。
value = 10 ;
このように、代入演算子で変数に値を保存することを代入するといいます。代入する値は、変数の型と互換性がなければなりません。例えば、int 型の変数は整数を保存するための記憶領域を表すので、これに文字列を保存することはできません。
int value; value = "Kitty on your lap";
上記の代入式は、整数型の変数 value に文字列を代入しようとしています。整数と文字列は型が異なるため、この代入はコンパイルエラーとなります。数値に比べて文字列の扱いは特殊なので、文字列を変数に保存する方法については後述します。
変数は名前の付いた値のように利用することができ、保存した値をいつでも取り出すことができます。これまでは文字列リテラルや数値リテラルを cout に出力してきましたが、同じように変数名から値を取り出し、画面に表示することができます。
#include <iostream>
int main()
{
int value;
value = 10;
std::cout << value << "\n";
return 0;
}
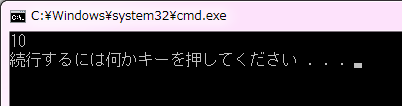
コード1は、整数型の value 変数を宣言し、これに値 10 を代入しています。以降 value 変数は 10 という値を表すようになります。cout に value 変数の値を出力した結果 10 という値が表示されていることが確認できます。
変数に保存されている値は、代入によって何度も上書きできます。変数に値を代入すると、元々変数に保存されていた値は消えてしまいます。
#include <iostream>
int main()
{
int value;
value = 10;
std::cout << value << "\n";
value = 20;
std::cout << value << "\n";
return 0;
}
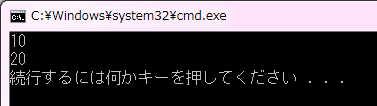
コード2では value 変数の値を代入演算子で値を 2 回書き換えています。最初の value = 10 という代入演算で value 変数の値を 10 に初期化し、直後に value 変数の値を出力しています。実行結果の 1 行目を見ての通り、value 変数の値は 10 です。続いて value = 20 という代入演算によって value 変数の値を 20 に書き換えます。このとき、前に代入した値 10 は消えてしまいます。実行結果の 2 行目を見れば、value 変数の値が変更されていることが確認できます。
このように、変数の値は自由に書き換えることができます。ただし、同じ変数をむやみに複数の用途に再利用してはいけません。1 つの変数は 1 つの役割に限定して利用するべきです。そうでなければ、プログラムが複雑になったとき、変数の値がいつ、どのコードによって書き換えられたのか理解することが難しくなってしまいます。
現在の PC の記憶容量は数ギガバイトが当然なので、整数型の変数 1 つや 2 つの領域を節約したところで影響はありません。それ以上に、読みやすく書き換えが容易なコードを書くことの方が生産的でしょう。もっとも、小型端末などに組み込まれるプログラムでは、場合によって数バイト単位の切り詰めが必要なこともあるかもしれません。
2.6.3 左辺値と右辺値
代入演算子は、算術演算子などの計算を行う演算子とは異なる性質を持っています。算術演算子は 1 + 2 のように左右の項がリテラルであっても問題ありませんでしたが、代入演算子は左項にリテラルを指定することはできません。リテラルは変数ではないので、値を代入できないためです。
10 = 20
代入演算子の意味を考えれば、上記の式が間違っていることは明らかでしょう。左項の値 10 は変数ではないため、これに値を代入することはできません。代入演算子の左項に指定できる値は、何らかの記憶領域を指す参照である必要があります。このような性質を持つ値を左辺値(Lvalue)と呼びます。代表的な左辺値は変数ですが、単純な変数以外にも左辺値となる値が存在します。この場では、代入演算子の左項に指定できるのは左辺値だけであり、左辺値とはすなわち変数だと考えてかまいません。
また、左辺値に対応する概念で右辺値(Rvalue)も存在します。右辺値とは、左辺値または非左辺値であると定義されます。つまり、あらゆる値は右辺値になれます。変数もリテラルも右辺値であり、算術演算子の項は右辺値を取ります。また、代入演算子の右項には右辺値を指定できます。
左辺値と右辺値の違いを、いくつかの例で紹介しましょう。
x = 10 + 5; x = y; x = y * z;
上記の式は、すべて正常にコンパイルできます。変数 x、y、z は、整数型であると仮定します。代入演算子の左項には x 変数を指定しています。変数は左辺値なので問題ありません。代入演算子の右項には任意の値、すなわち右辺値を指定できます。算術演算の結果、変数、整数リテラルなど、左辺値も左辺値ではない値も含め、すべての値は右辺値です。
10 = x; x + y = 10;
一方、上記の式はエラーとなります。整数リテラルは左辺値ではないため代入演算子の左項に指定することはできません。整数の加算結果も右辺値なので、これに値を代入することはできません。
2.6.4 初期化子
最初に変数に値を代入するまでは、変数にどのような値が格納されているかは不定です。変数に最初の値を与えることを初期化と呼びます。初期化されていない変数には意味のない適当な値が格納されていますが、これを利用してはいけません。変数は、必ず初期化してから値を取り出してください。
int value; std::cout << value << "\n";
上記のような変数の利用は明らかに間違いです。変数に値を代入する前に、変数の値を出力しようとしています。Visual C++ でこれを実行すると変数を初期化する前に使おうとしている旨の警告が表示されます。他の環境では正常に実行できることもありますが、不定の値が格納されている変数を利用することなど有り得ないので、必ず初期化しましょう。
変数を宣言したときに、変数に保存する最初の値が決定しているのであれば、初期化子(initializer)を用いて変数を宣言すると同時に、変数が保持する最初の値を設定できます。初期値が決まっていない場合でも 0 などの値で初期化しておけば、初期化忘れによるバグなどを防げます。
初期化子は大きく 2 種類に分けられます。1 つは変数宣言時に変数名に続けて = 記号と初期値を記述する方法です。整数型のような単純な値の変数を初期化するには、この書き方が一般的です。
型 変数名 = 式;
これは、前述した代入演算子に近い書き方なので直観的に理解できるでしょう。= 記号に続く式に指定した値が変数の初期値として設定されます。この時の = 記号は代入演算子ではなく、宣言構文の一部である初期化子の構文として定められている区切り子です。式の結果は、宣言する変数の型に互換性がなければなりません。
#include <iostream>
int main()
{
int value = 100;
std::cout << value << "\n";
return 0;
}
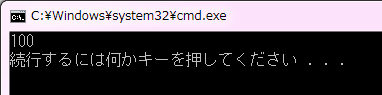
加えて、変数名の後に ( ) で括った中に初期化する値となる式を記述する次のような書き方もあります。本来、この初期化子はコンストラクタと呼ばれる機能を持つ複雑なデータの初期化に使われます。通常、整数のような単純な値の変数に対して、この初期化方法が使われることはありません。
型 変数名(式リスト);
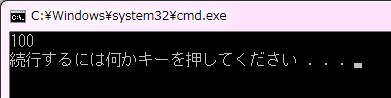
変数名の後の ( ) 内には、初期化に使用する値を指定します。この初期化方法では、必要であればカンマ区切りで複数の値を渡すこともできます。今は、このような初期化方法も存在するという程度の認識でよいでしょう。
#include <iostream>
int main()
{
int value(100);
std::cout << value << "\n";
return 0;
}
2.6.5 変数の型とサイズ
変数を宣言するときに書いた int キーワードは、宣言する変数の型を表しています。int キーワードは C++ 言語で定められている整数を表す型です。コンピュータの世界ではあらゆる情報を 2 進数で表しているため、その値の扱い方を区別しなければなりません。リテラルでも説明したように、整数、浮動小数点数、文字など、扱うデータの種類によって型が異なります。
int のような型指定子は、宣言する変数がどのようなデータを扱うのかを表しています。整数型の場合は int を指定しましたが、1 文字を保存する変数ならば char キーワードを使い、浮動小数点数を保存する変数ならば double キーワードを使うことになるでしょう。このような C++ 言語のキーワードであらかじめ定められている型を基本型(fundamental types)と呼びます。
| 型指定子 | 意味 |
|---|---|
| char | 1 文字を保存できる整数型。 |
| wchar_t | ワイド文字 1 文字を保存できる整数型。 |
| bool | true または false を持つ整数型。 |
| short | char よりも大きいか等しく、int よりも小さいか等しい整数型。 |
| short int | |
| int | short よりも大きいか等しく、long よりも小さいか等しい整数型。 |
| long | int よりも大きいか等しく、long long よりも小さいか等しい整数型。 |
| long int | |
| long long | long よりも大きいは等しい整数型。 |
| long long int | |
| float | 最小の浮動小数点型。 |
| double | float よりも大きいか等しく、long double よりも小さいか等しい浮動小数点型。 |
| long double | double よりも大きいか等しい浮動小数点型。 |
表1は、C++言語のキーワードとして事前に用意されている基本型です。基本型は、大きく分けると整数型と浮動小数点型に分けることができます。char、wchar_t、bool、short、int、long は整数型に属し、残る float、double、long double が浮動小数点型に属します。一部の型は意味が重なっています。short 型は short int、long 型は long int、long long 型は long long int と書くこともできます。
変数の型の違いは、変数に格納されているデータの種類を表すのと同時に、そのデータを格納するために必要な記憶領域の容量も表しています。例えば 1 バイト(8 ビット)の記憶領域は 8 桁の 2 進数と考えることができるので、最大で 256 通りの表現ができます。よって 1 バイトの整数では、どうやっても 255 までしか値を数えることができないのです。より大きな数を保存する場合、より大きな記憶領域を必要とします。そのため、同じ整数型でも変数が確保する記憶領域の大きさによって char や int などの異なる型が用意されているのです。
ところが、ここで少しややこしい問題があります。C++ 言語の国際標準では、これらの型の相対的な違いは決められていますが、具体的なサイズは決められていないのです。従って、コンパイラによって int 型の変数のサイズが 2 バイトになるかもしれないし、4 バイトになるかもしれないのです。標準では int は short よりも大きく long よりも小さい、またはそれらと等しいサイズであれば良いと定めているだけなのです。bool にいたってはサイズが決められていません。
基本型が確保する領域のサイズを知るには開発環境のドキュメントを読むか、実際にプログラムして割り当てられたサイズを調べるしかありません。例えば Visual C++ 2010 では表2のように決められています。
| 型 | サイズ |
|---|---|
| char | 1 バイト |
| wchar_t | 2 バイト |
| bool | 1 バイト |
| short | 2 バイト |
| int | 4 バイト |
| long | 4 バイト |
| long long | 8 バイト |
| float | 4 バイト |
| double | 8 バイト |
| long double | 8 バイト |
Visual C++ では、同じ整数型でも 2 バイトの short 型と 4 バイトの int 型では、保存できる値の限界が異なります。2 バイト(16 ビット)では 65536 通りの数しか表現できませんが、4 バイト(32 ビット)あれば約 43 億通りの数が表現できます。各基本型の限界値については、後述する表3をご覧ください。
char 型と wchar_t 型は、主に 1 文字の保存として利用される整数型です。伝統的に C 言語の時代から使われていた char 型は 1 文字分のデータ量を表しますが、この時代の言語はラテン文字文化圏しか想定されていなかったため、複数の言語を組み合わせた国際化が考慮されていません。後に追加された wchar_t 型は国際化に対応したワイド文字を保存するために用いられます。しかし、char 型と wchar_t 型には互換性がないため、C++ 言語では日本語や中国語のような漢字文化圏の文字の扱いに注意が必要です。
bool 型は、true または false からなるブーリアンリテラルに相当する値を保存するための整数型です。ブーリアンリテラルの実体は整数であったことを思い出してください。bool 型の変数が保存する値は true または false のいずれかですが、その中身は 1 または 0 を保存する 1 バイトの整数型です。
float 型と double 型は浮動小数点型に分類されるため、同じバイト数でも整数型とは扱いが異なります。例えば float 型と int 型は同じ 4 バイトの領域を確保しますが、float 型の変数に保存される値は浮動小数点数です。整数と浮動小数点数はビットの扱いが異なり、プログラムは float 型や double 型の変数には浮動小数点数が格納されているものとして解釈します。
#include <iostream>
int main()
{
char c = 'A';
std::cout << "c = " << c << "\n";
bool b = true;
std::cout << "b = " << b << "\n";
short int s = 12345;
std::cout << "s = " << s << "\n";
int i = 1234567890;
std::cout << "i = " << i << "\n";
long int li = 1234567890;
std::cout << "li = " << li << "\n";
long long int lli = 12345678900;
std::cout << "lli = " << lli << "\n";
float f = 3.14;
std::cout << "f = " << f << "\n";
double d = 0.123e-64;
std::cout << "d = " << d << "\n";
return 0;
}
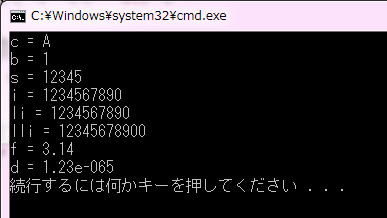
コード5は、主な基本型の変数を用意し、これに適当な値を代入して表示するプログラムです。
2.6.6 符号付きと符号なし
コンピュータの世界では、あらゆる情報が 2 進数のビットで表現されています。単項 - 演算子で符号を反転させ、正の数を負の数に変換できることは前に説明しました。では、2 進数の世界で負数はどのように表現されているのでしょうか。
ビットの世界にはマイナスという概念はありません。例えば 2 ビットの値は 00、01、10、11 という 4 通りの状態を表現できるというだけで、それが数なのか別の何かを意味しているのかは型によって決まります。
数値型の値は、最上位ビットの値を符号の判定に利用することで、値が正なのか負なのかを判断しています。最上位ビットが 0 であれば正数、1 であれば負の数であると認識します。ところが、符号判定に 1 ビット使ってしまうため、絶対値の限界は半分になってしまいます。
例えば 8 ビットの整数型で最上位ビットを符号に利用した場合、正の数で表現できるのは 0111 1111 が限界になります。これは 10 進数で 127 です。ところが、負の数を扱わないことが確定している変数にとっては 1 ビットを符号に利用することが無駄になってしまいます。同じ 8 ビットでも最上位ビットを符号に利用しなければ 255 まで数えられます。そこで、変数宣言時に符号が必要かどうかを設定できます。
最上位ビットを符号に利用する変数は符号付き変数と呼び、符号を持たない変数を符号なしと呼びます。整数型の変数は、特に指定がなければ自動的に符号付きであると解釈されますが signed キーワードを使って明示的に符号付きであることを宣言できます。符号なし変数であることを宣言するには unsigned キーワードを使います。これらのキーワードは表3のように整数型と組み合わせて利用します。
| 型 | 範囲 |
|---|---|
| char | -128 ~ 127(コンパイラの設定で 0 ~ 255 までに変更可能) |
| signed char | -128 ~ 127 |
| unsigned char | 0 ~255 |
| short | -32768 ~ 32767 |
| short int | |
| signed short | |
| signed short int | |
| unsigned short | 0 ~ 65535 |
| unsigned short int | |
| int | -2147483648 ~ 2147483647 |
| signed | |
| signed int | |
| unsigned | 0 ~ 4294967295 |
| unsigned int | |
| long | -2147483648 ~ 2147483647 |
| long int | |
| signed long | |
| signed long int | |
| unsigned long | 0 ~ 4294967295 |
| unsigned long int | |
| signed long long | –9223372036854775808 ~ 9223372036854775807 |
| signed long long int | |
| unsigned long long | 0 ~ 18446744073709551615 |
| unsigned long long int |
signed と unsigned もまた型指定子であり、これらの型指定子が記述される並びは自由です。例えば unsigned int を int unsigned と記述しても文法上は問題ありません。しかし、一般には signed または unsigned を先に書くことが慣習となっています。signed だけの場合は signed int と同じであり、unsigned だけの場合は unsigned int と同じ意味になります。
整数型の型指定子の組み合わせは表3以外は考えられません。例えば signed と unsigned を同時に設定することはできませんし、short long のような組み合わせも許されません。
符号付きの場合、最上位の 1 ビットを符号に利用するため、負の数が表現できるようになる代わりに数えられる最大の絶対値が半分になっています。
#include <iostream>
int main()
{
signed short int si;
si = 32767;
std::cout << si << "\n";
si = 32768;
std::cout << si << "\n";
si = 32769;
std::cout << si << "\n";
return 0;
}
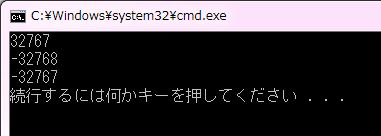
コード6は、符号付きの short int 型変数 si に対して、正の数の最大値 32767 以上を代入してします。32767 までは正常に表示されますが、32768 以降は符号が反転して正常に表示できていません。32768 は 16 ビットの最上位ビットを 1 にしてしまうため、符号付きの変数では符号が反転してしまいます。
#include <iostream>
int main()
{
unsigned short int ui;
ui = 65535;
std::cout << ui << "\n";
ui = 65536;
std::cout << ui << "\n";
ui = 65537;
std::cout << ui << "\n";
return 0;
}
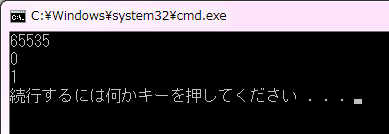
コード7は、符号なしの short int 型変数 ui に対して最大値 65535 以上を代入しています。65535 の時点ですべてのビットが 1 になります。これ以降の値を代入しても、16 ビット以降のビットは切り捨てられるため 65536 の代入結果は 0 になっています。
2.6.7 複合代入演算
単純代入は変数の値を新しい値で上書きしますが、時に変数の現在の値を軸に計算を行う必要があります。例えば、変数に保存されている現在の値に 10 を加えたい場合です。変数の値が 5 だとすれば、これに 10 を加えた結果は 15 となります。このような操作に 2 つの変数を用意する必要はありません。次のように書けばよいのです。
int i = 5; i = i + 10;
変数 i は 5 で初期化されており、これに 10 を加えたければ i + 10 を求めます。そして、この結果を i に保存すれば、最終的な i の値は 15 となります。
上記と同じ計算を 1 つの代入演算子で行うこともできます。例えば、上記のような加算代入は i += 10 と書くことができます。このような、変数の現在の値に何らかの演算を行って代入する演算子のことを複合代入演算子と呼ぶこともあります。
| 演算子 | 意味 |
|---|---|
| = | 単純代入(simple assignment) |
| += | 加算代入(addtion assignment) |
| -= | 減算代入(subtraction assignment) |
| *= | 乗算代入(multiplication assignment) |
| /= | 除算代入(division assignment) |
| %= | 剰余代入(modulus assignment) |
| <<= | 左シフト代入(left shift assignment) |
| >>= | 右シフト代入(right shift assignment) |
| &= | ビット単位の論理積代入(bitwise AND assignment) |
| ^= | ビット単位の排他的論理和代入(bitwise exclusive OR assignment) |
| |= | ビット単位の論理和代入(bitwise inclusive OR assignment) |
表4は代入演算子の一覧です。単純代入演算子 = 以外は、すべて変数の現在の値と右オペランドを計算した結果を新しい変数の値とします。複合代入を行う演算子は、すべて op= の形をとります。op には計算を行う算術演算子や論理演算子、シフト演算子が入ります。
#include <iostream>
int main()
{
int i;
i = 10;
std::cout << "i = 10 : " << i << "\n";
i += 20;
std::cout << "i += 20 : " << i << "\n";
i -= 5;
std::cout << "i -= 5 : " << i << "\n";
i *= 2;
std::cout << "i *= 2 : " << i << "\n";
i >>= 1;
std::cout << "i >>= 1 : " << i << "\n";
return 0;
}
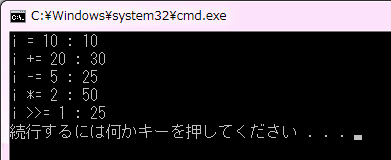
コード8は、加算代入 += 演算子や減算代入 -= 演算子などを使って、変数の値がどのように変化するのかを調べます。最初に = 演算子で 10 を単純代入しています。この時点で変数 i の値は 10 です。続いて += 演算子で 20 を加算代入しています。変数 i の値は 10 だったので、これと 20 を加算した結果が i に代入されます。従って i += 20 の結果は 30 となっています。その後も同様で、変数 i の値に対して減算代入、乗算代入、右シフト代入を行っています。