
基本データ型と文字列

基本的な数値型
Windows API では C 言語のキーワードとして定められている基本型とは異なるデータ型を使っています。しかし、それは特別な Microsoft 固有の仕様などではなく typedef や #define ディレクティブを用いて与えられた別名に過ぎません。その実体をアプリケーション開発者が知る必要はありませんが、多くは数値型です。
C 言語の int や long などの型は、コンパイルする環境によってサイズが異なります。CPU やシステムによっては、int は 16 ビットの可能性も 32 ビットである可能性もあります。サイズが異なることを問題としない場合は良いのですが、ビット演算などを行うプログラムでは問題になることがあります。
Win32 API では、こうしたネイティブな型を隠蔽し、ビットサイズや目的を明確にした型を定義しているのです。型に互換性があり、コンパイラが警告を発しない限り、C 言語のネイティブな型を用いても問題はありませんが、基本的に Windows プログラミングでは、Windows が定めている型を利用します。コンパイル環境が異なっても、互換性(コードの携帯性)を保つことができるというメリットがあります。Win32 が定義する主な型を表1に表します。
| Win32 型 | 対応するポインタ型 | constポインタ型 | 解説 |
|---|---|---|---|
| BOOL, BOOLEAN | PBOOL, LPBOOL | 論理値型。TRUE または FALSE を格納する | |
| BYTE | PBYTE, LPBYTE | LPCBYTE | 8ビット符号無し整数 |
| WORD | PWORD, LPWORD | 16ビット符号無し整数 | |
| DWORD | PDWORD, LPDWORD | 32ビット符号無し整数 | |
| DWORDLONG | PDWORDLONG | 64ビット符号無し整数 | |
| CHAR | PCHAR | char に対応 | |
| UCHAR | PUCHAR | unsigned char に対応 | |
| WCHAR | PWCHAR | PCWCHAR, LPCWCHAR | wchar_t に対応 |
| SHORT | PSHORT | short int に対応 | |
| USHORT | PUSHORT | unsigned short int に対応 | |
| INT | PINT, LPINT | signed int に対応 | |
| UINT | PUINT, LPUINT | unsigned int に対応 | |
| LONG | PLONG, LPLONG | long に対応 | |
| LONGLONG | PLONGLONG | long long に対応 | |
| ULONGLONG | PULONGLONG | unsigned long long に対応 | |
| FLOAT | PFLOAT | float に対応 | |
| DOUBLE | PDOUBLE | double に対応 | |
| VOID | PVOID, LPVOID | LPCVOID | void に対応 |
Windows API における関数の宣言や構造体では、これらの別名を利用しています。特に、数値型の多くは DWORD など、ビット数が固定されている実体を隠蔽する型を好んで使っています。BOOL または BOOLEAN 型は、真偽を保存する論理値を表すために用いられます。TRUE や FALSE もマクロとして定義されています。
さらに、型識別子の先頭に P または LP という接頭辞を指定するとポインタ型になるという規則があります。例えば DWORD 型へのポインタは PDWORD 型として表現することができます。これは、単純に DOWRD* と同じですが、Win32 API の宣言では LP 接頭辞が積極的に使われているため、覚えておいて損はありません。
LP と P の接頭辞に違いはありません。LPDWORD、PDWORD、そして DWORD * はまったく同じであると考えられます。P は Pointer の頭文字でありますが、L は何を表しているのでしょうか。これは 16 ビット時代からの名残で L は Long の頭文字からきており、LP とは Long Pointer のことを表しています。当時は 16 ビットポインタを near ポインタと呼び、32 ビットポインタを far ポインタと呼んで、分けて扱わなければなりませんでした。そこで PINT は int near* を表し、LPINT は int far* を表す、という形で区別していたのです。これは 16 ビット Windows 時代の名残であり、現在ではどちらも同じです。
文字列型と文字集合
標準 C では、多くの文字を表現しなければならない多言語のコードを表現する手段としてワイド文字と呼ばれる wchar_t 型を定めています。この型は 1 文字を 16 ビットで表現でき、事実上 Unicode を保存する手段として用いられます。Unicode は世界中のあらゆる文字を表現するために規格化された文字コードで、1 文字を表現するために、基本的に 2 バイトを使います。Unicode は、アルファベット以外の特殊記号や文字を多用する国の言語を、統一した手段で制御する有効な手段となります。
Windows XP 以降、すべての Windows は Unicode に対応しており、フォントがインストールされていれば、アプリケーションは複数の言語を組み合わせて表示できます。基本的に、新しいプロジェクトであれば Unicode 文字集合でビルドされるべきですが、Windows 9x 時代のプログラムでは対応されていないという問題があります。古いシステムや Unicode をサポートしないシステムに移植(またはその逆の作業を)するには、コードを書き直さなければならなくなってしまいます。
このような古い文字集合と Unicode の問題を解決するため、Windows API は独自の文字型を用いて実体を隠蔽しています。マルチバイト文字としてコンパイルする場合は 1 バイト型(すなわち char 型)、Unicode としてコンパイルする場合は 2 バイト型(すなわち wchar_t 型)になるように、プリプロセッサ命令で細工しています。もし UNICODE マクロが定義されているならば Unicode として文字列を処理するのです。
表2は Windows で用いられる文字型、および文字列型です。
| 文字列型 | 解説 |
|---|---|
| TCHAR, TBYTE | UNICODE が定義されていれば WCHAR、そうでなければ CHAR |
| PSTR, LPSTR | NULL で終わるマルチバイト文字列へのポインタ |
| PCSTR, LPCSTR | NULL で終わる変更できないマルチバイト文字列へのポインタ |
| PWSTR, LPWSTR | NULL で終わるワイド文字列へのポインタ |
| PCWSTR, LPCWSTR | NULL で終わる変更できないワイド文字列へのポインタ |
| PTSTR | UNICODE が定義されていれば PWSTR、そうでなければ PSTR |
| PCTSTR | UNICODE が定義されていれば PCWSTR、そうでなければ PCSTR |
| LPTSTR | UNICODE が定義されていれば LPWSTR、そうでなければ LPSTR |
| LPCTSTR | UNICODE が定義されていれば LPCWSTR、そうでなければ LPCSTR |
表を見ると多くの型があってややこしいのですが、基本は PTSTR(LPTSTR) または PCTSTR(LPCTSTR) を用いることになります。PTSTR は単純に TCHAR の配列へのポインタであると考えることができます。上書きが不可能な文字列リテラルを指す変数や、変更を好まない文字列へのポインタはPCTSTR を用いればよいでしょう。
これで、Unicode を採用するプログラムにはワイド文字(wchar_t)、そうでなければマルチバイト文字(char)でコンパイルすることができますが、文字列リテラルが代入するポインタ型に合致しなくなる可能性があります。例えば、次のような処理は問題があります。
PCTSTR pctstr = "Kitty on your lap";
上記のコードは、文字列リテラルが常にマルチバイト文字となります。UNICODE マクロが定義されていなければ問題ありませんが、もし PCTSTR が PCWSTR すなわち const wchar_t * として解釈されたのであれば、文字列リテラルに L 接頭辞をしていしなければなりません。この問題を解決するには、UNICODE が定義されている場合は L 接頭辞を文字列に付加し、そうでなければそのままの文字列として解釈する必要があります。これを実現するには TEXT() マクロを用います。
TEXT( string );
string パラメータには任意の文字リテラル、または文字列リテラルを指定します。TEXT() マクロは最終的に UNICODE 識別子が定義されている場合はワイド文字(ワイド文字列に変換し、そうでなければ変換しません。このマクロ関数は次のように定義されていると考えることができます。
#ifdef UNICODE
#define TEXT(quote) L##quote
#else
#define TEXT(quote) quote
#endif
## 演算子は左右のトークンをテキストレベルで連結させるプリプロセッサ演算子です。UNICODE 識別子が定義されている場合は、文字列の先頭部分に L を追加します。ソース内のすべての文字列リテラルに TEXT() マクロを用いれば、必要に応じてワイド文字とマルチバイト文字を切り替えられます。
Windows API における TCHAR 型による UNICODE 文字集合とマルチバイト文字集合の切り替えの仕組みを汎用テキストマッピング(Generic-Text Mappings)と呼びます。標準 C の文字列を扱う関数やライブラリと Windows API を相互運用するような場合、汎用テキストマッピングの仕組みを正しく理解していなければなりません。
デバッグ出力
ウィンドウを表示してテキストを描画するまでには相当のコードを記述しなければなりません。テキストの描画は標準 C の printf() 関数のような簡単なものではありません。そこで、printf() 関数のように文字列を画面に表示する方法が必要です。
アプリケーションがデバッグ用にビルドされている場合 OutputDebugString() 関数に文字列を渡すことで Visual Studio の出力ウィンドウに表示されます。
VOID OutputDebugString(LPCTSTR lpOutputString);
lpOutputString パラメータに出力する文字列を指定します。
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
OutputDebugString(TEXT("Stand by Ready!!\n"));
return 0;
}
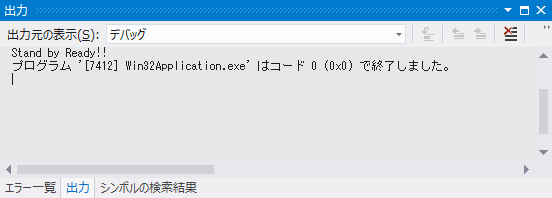
コード1は OutputDebugString() 関数に TEXT() マクロの結果を渡しています。TEXT() マクロはパラメータに指定された文字列を必要に応じてワイド文字列に変換するため、その結果は LPCTSTR 型として扱えます。
Windows API で TCHAR や LPTSTR などの汎用テキストマッピングを用いた関数は、内部でワイド文字型に対応する関数とマルチバイト文字型に対応する関数に分けられています。このとき、ワイド文字を受ける関数は関数の末尾に W 接尾辞を、マルチバイト文字を受ける関数は A 接尾辞を付加するという命名規則がみられます。
例えば OutputDebugString() 関数は UNICODE 識別子が定義されていれば OutputDebugStringW() 関数に変換され、そうでなければ OutputDebugStringA() 関数に変換され、ネイティブの文字列型が引数に対応する形になります。
VOID OutputDebugStringW(LPCWSTR lpOutputString);
VOID OutputDebugStringA(LPCSTR lpOutputString);
OutputDebugStringW()関数のパラメータはワイド文字列の LPCWSTR 型であり、OutputDebugStringA() 関数のパラメータはマルチバイト文字列の LPCSTR 型であることが確認できます。OutputDebugString() 関数の実体は #define ディレクティブによるマクロであり、UNICODE 識別子が定義されているかどうかによってプリプロセッサによって切り替えられています。
#ifdef UNICODE #define OutputDebugString OutputDebugStringW #else #define OutputDebugString OutputDebugStringA #endif
なので、コードをビルドする環境が Unicode 文字集合、またはマルチバイト文字集合のどちらか確定しているのであれば、OutputDebugStringW() 関数や OutputDebugStringA() 関数を直接呼び出すことも可能です。
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
OutputDebugStringW(L"この手に魔法を!\n");
OutputDebugStringA("Stand by Ready!!\n");
return 0;
}
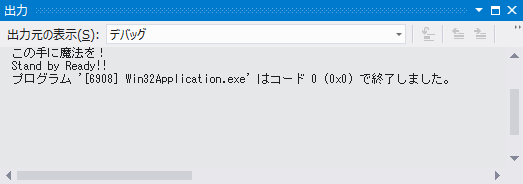
コード2は OutputDebugString() 関数ではなく、マッピング先である OutputDebugStringW() 関数と OutputDebugStringA() 関数を直接呼び出しています。本来、このようなコードを書くべきではありません。開発者は汎用テキストデータ型を用い、ワイド文字にもマルチバイト文字にも対応できる(文字集合の違いを意識しなくてもよい)プログラムを書くべきです。
Unicode 文字集合とマルチバイト文字集合の設定
Visual Studio(Visual C++)を使って開発している場合、プロジェクトのプロパティから Unicode 文字集合(ワイド文字)を使うのか、マルチバイト文字集合を使うのかを設定できます。「ソリューション エクスプローラ」からプロジェクトを選択した状態で「プロジェクト」メニューの「プロパティ」項目を選択してください。
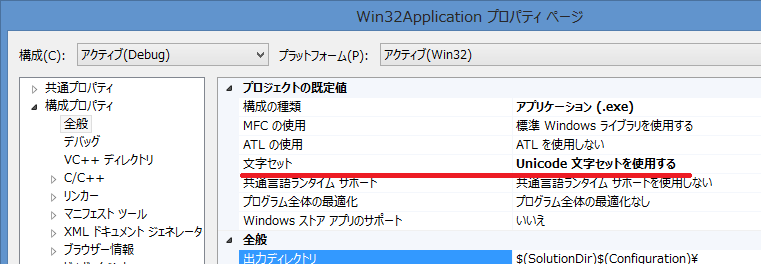
プロジェクトの「プロパティ ページ」ダイアログボックスが表示されるので、左側のリストから「構成プロパティ」→「全般」項目を選択し、表示されたプロパティ一覧から「文字セット」に注目してください。このプロパティに「Unicode 文字セットを使用する」が選択されている場合は UNICODE 識別子が定義され、プログラムの文字には Unicode 文字集合が使用されます。すなわち汎用テキストデータ型は wchar_t 型として扱われます。一方、「マルチ バイト文字セットを使用する」が設定されている場合は UNICODE 識別子が定義されず、プログラムの文字にはマルチバイト文字集合が使用されます。
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
#ifdef UNICODE
OutputDebugString(TEXT("Unicode 文字列です。\n"));
#else
OutputDebugString(TEXT("マルチバイト文字列です。\n"));
#endif
return 0;
}
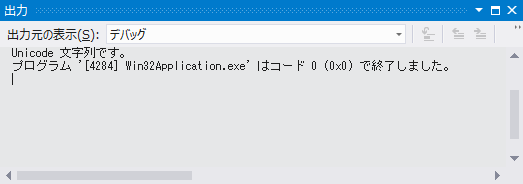
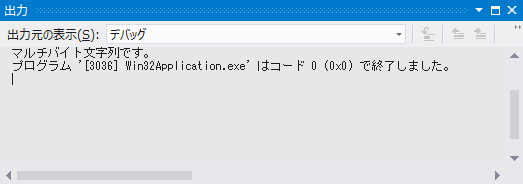
コード3は #ifdef ディレクティブを用いて Unicode が使用される場合と、そうでない場合でコンパイルするコードを切り替えています。プロジェクトの設定を変更することで、出力される文字列が切り替わることを確認してください。
文字列操作
Windows API の文字列型を使うには、まだいくつかの課題が残ります。TCHAR 型の文字列を扱う場合、C 言語の標準文字列関数を使うことができなくなってしまいます。例えば strlen() 関数で文字数を数えると、関数がワイド文字に対応していないため Unicode 文字集合が使えません。数値を文字列に変換したい場合なども sprintf() 関数が使えないのです。
そこで、Windows API は標準関数に代わる PTSTR 型の文字列に対応した文字列関数郡を提供しています。C の標準関数に置き換えられる Win32 の代表的な文字列操作関数を表3にまとめます。これらの関数の仕様は char * 型の代わりに LPTSTR 型が用いられていることを除いて標準関数と同じです。
| Win32関数 | 標準関数 | 解説 |
|---|---|---|
| lstrcat | strcat | 文字列に他の文字列を追加する |
| lstrcmp | strcmp | 文字列を比較する |
| lstrcpy | strcpy | 文字列を複製する |
| lstrcpyn | strncpy | 文字列を指定した文字数だけ複製する |
| lstrlen | strlen | 文字列の長さを返す |
| wsprintf | sprintf | 引数を書式制御文字列にしたがってフォーマットし、バッファに格納する。 |
LPTSTR lstrcat(LPTSTR lpString1, LPCTSTR lpString2);
int lstrcmp(LPCTSTR lpString1, LPCTSTR lpString2);
LPTSTR lstrcpy(LPTSTR lpString1, LPCTSTR lpString2);
LPTSTR lstrcpyn(LPTSTR lpString1, LPCTSTR lpString2, int iMaxLength);
int lstrlen(LPCTSTR lpString);
int wsprintf(LPTSTR lpOut, LPCTSTR lpFmt, ...);
特に重要なのは wsprintf() 関数の存在です。sprintf() は書式指定文字列に従ってバッファに文字列を保存することができたため、数値や文字列を簡単に変換することができました。これを Windows API のデータ型で行うには wsprintf() 関数を使います。
また、lstrlen() 関数と strlen() 関数の違いに注目する必要があります。char 型の文字列は 1 バイトが 1 文字として計算されるため、strlen() 関数が返す文字列の文字数とは、すなわち文字列を表現するために必要なバイト数と同じでした。しかし lstrlen() 関数は Unicode 文字集合が使用されている場合、文字数は文字列を表現するために必要なバイト数とは同値にはなりません。Unicode は 1 文字を表現するために 2 バイト使うため、文字数が 5 文字だとすれば、それを表現するには 10 バイト(ヌルで終わる場合は 12 バイト)必要になります。この問題を回避するには、文字列を表現するために必要なバイト数を lstrlen(lpString) × sizeof(TCHAR) という計算で求めるようにします。Unicode 文字列の場合はヌル文字も 2 バイトの 0 でなければ認識されないことにも注意が必要です。
#include <windows.h>
int WINAPI WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow)
{
PCTSTR str = TEXT("Stand by Ready!!");
TCHAR buffer[1024];
DWORD strLength;
strLength = lstrlen(str);
wsprintf(
buffer , TEXT("文字列=%s\n文字数=%d, 文字列のサイズ=%d\n") ,
str , strLength , strLength * sizeof(TCHAR)
);
OutputDebugString(buffer);
return 0;
}
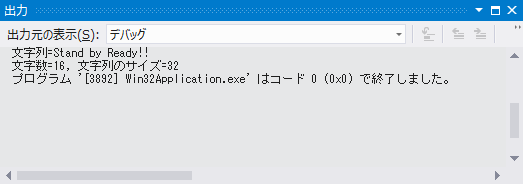
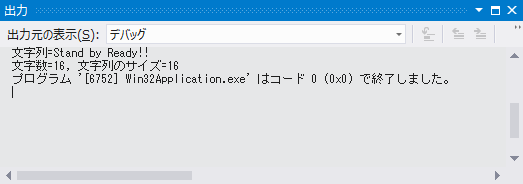
コード4は、「Unicode 文字セットを使用する」を設定してビルドした場合と、「マルチ バイト文字セットを使用する」を設定してビルドした場合とで、文字列の表現に必要なサイズが変化することを確認できます。汎用テキストマッピングのおかげで、このコードの文字列操作は完全に Unicode とマルチバイト文字の両方に対応しています。
文字列の長さを取得する時は lstrlen() 関数を、書式制御文字列を用いて変換を行うには wsprintf() 関数を使っています。受け渡しする文字列が汎用テキストデータ型である点を除けば、標準関数の文字列操作と大差はありません。